
2019-10-22 21:28:03
评论
4,108次浏览
对于网络爬虫,程序员们都不陌生,毕竟我们互联网的鼻祖谷歌和百度这样的搜索引擎,都是通过爬虫技术来获取其他网页索引资源的。
网络爬虫实际名称为spider,这种技术的原理就是一个虚拟机器人,也就是一个程序来模仿人的访问轨迹来访问网站,在访问到新内容(未入库的信息)的时候,spider爬虫将内容反馈到服务终端并且入库,我们看到的搜索引擎索引就是通过这种原理来抓取快照同时又通过逆向索引的方式来索引出用户搜索的内容。(逆向索引的概念与本文关系不大,这里就不讲了。)
在互联网上,spider爬虫一般获取信息的方式除了是来自资源站建立的直接关联之外,还有就是通过网页上的超链接来爬取,也就是一个网页上的超链接爬到另一个网页,再从另一个网页里面的超链接爬到更多,这样形成一张极大的数据网络,从而扩充自己的内容库。
那么网络爬虫技术如何规范使用呢?如何规避侵犯他人网站隐私等相关问题呢?
这就要说一个协议,也就是robots协议,这个协议是在一个网页中级别很高的权限文件,他可以告诉spider哪些目录是禁止爬取的。
这里看一下其中一个例子:
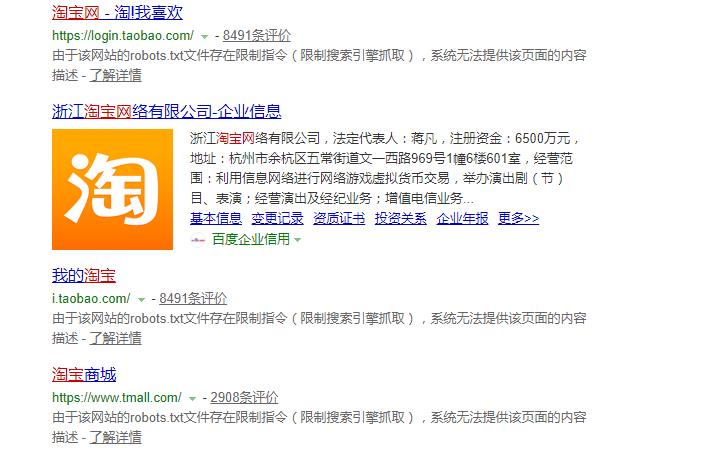
大家可以看到,淘宝针对某搜索引擎就使用禁止索引机制,那么这个搜索引擎就遵守了robots规则对其内容没有抓取。
也就是,如果想规范使用爬虫技术必须遵守robots协议。

![[安全]关于kali linux的一些常用命令](https://www.jinshare.com/wp-content/themes/begin/timthumb.php?src=https://www.jinshare.com/wp-content/uploads/2021/01/1.png&w=280&h=210&zc=1)


蚂蚁森林为我浇水吧!